|
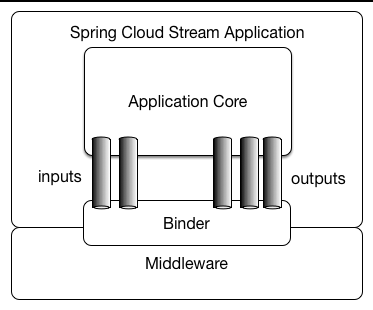
Spring Cloud Stream 提供了许多抽象和原始方法,这些抽象和原始方法简化了消息驱动的微服务应用程序的编写。本节概述了以下内容: Spring Cloud Stream 应用程序由中间件中性核心组成。应用程序通过 Spring Cloud Stream 注入的输入和输出通道与外界进行通信。通道通过中间件特定的绑定器实现连接到外部代理。 Spring Cloud Stream 应用程序可以从你的 IDE 以独立模式运行以进行测试。要在生产中运行 Spring Cloud Stream 应用程序,可以使用为 Maven 或 Gradle 提供的标准 Spring Boot 工具创建可执行(或 “fat”)JAR。有关更多详细信请参阅 Spring Boot 参考指南。 Spring Cloud Stream 为 Kafka 和 Rabbit MQ 提供绑定器实现。Spring Cloud Stream 还包括一个 TestSupportBinder,它使一个通道保持不变,这样测试就可以直接和通道交互,并可靠地断言接收到的内容。还可以使用可扩展 API 编写自己的绑定器。
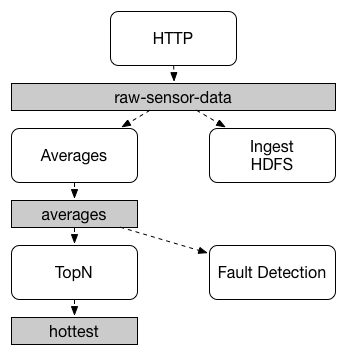
Spring Cloud Stream 使用 Spring Boot 进行配置,绑定器抽象使得 Spring Cloud Stream 应用程序能够灵活地连接到中间件。例如,部署人员可以在运行时动态选择通道连接到的目标(例如 Kafka 主题或 RabbitMQ 交换)。这种配置可以通过外部配置属性和 Spring Boot 支持的任何形式提供(包括应用程序参数、环境变量和 Spring Cloud Stream 自动检测并使用类路径上找到的绑定器。你可以使用具有相同代码的不同类型的中间件。为此,在构建时包含一个不同的绑定器。对于更复杂的用例,也可以在应用程序中打包多个绑定器,并让它在运行时选择绑定器(甚至是否为不同的通道使用不同的绑定器)。 应用程序之间的通信遵循发布订阅模型,其中数据通过共享主题进行广播。下图展示了一组相互作用的 Spring Cloud Stream 应用程序的典型部署。
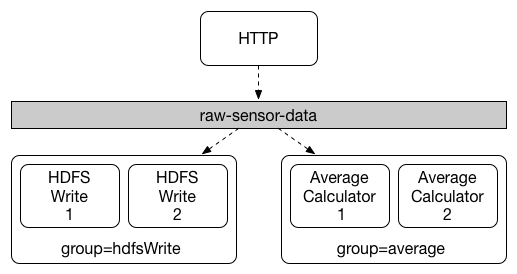
传感器向 HTTP 端点报告的数据将发送到名为 发布-订阅通信模型降低了生产者和消费者的复杂性,并允许在不中断现有流的情况下将新应用程序添加到拓扑中。例如,在 “平均计算” 应用程序的下游,可以添加一个计算最高温度值的应用程序,用于显示和监视。然后你可以添加另一个应用程序,该应用程序解释相同的平均流以进行故障检测。通过共享主题而不是点对点队列进行所有通信可以减少微服务之间的耦合。 尽管发布-订阅消息传递的概念并不新鲜,但 Spring Cloud Stream 采取了额外的步骤,使其成为应用程序模型的一个直观的选择。通过使用本地中间件支持,Spring Cloud Stream 还简化了不同平台上发布订阅模型的使用。 虽然发布订阅模型使通过共享主题连接应用程序变得容易,但是通过创建给定应用程序的多个实例来扩展应用程序的能力同样重要。当这样做时,应用程序的不同实例被放置在一个相互竞争的消费者关系中,在这个关系中,只需要一个实例来处理给定的消息。
Spring Cloud Stream 通过消费者组的概念来模拟这种行为。(Spring Cloud Stream 消费者组类似于 Kafka 消费者组,并受其启发。)每个消费者绑定都可以使用 订阅给定目标的所有组都将接收已发布数据的副本,但每个组中只有一个成员从该目标接收给定消息。默认情况下,如果未指定组,Spring Cloud Stream 会将应用程序分配给一个匿名且独立的单成员消费组,该消费组与所有其他消费组都处于发布-订阅关系中。 支持两种类型的消费者:
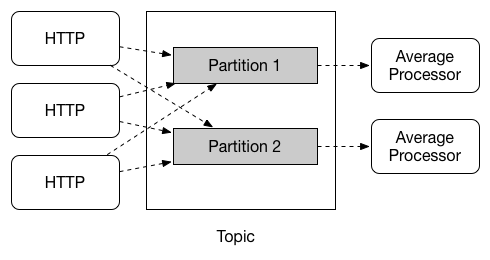
在版本 2.0 之前,仅支持异步消费者。消息一旦可用,线程就可以处理消息。 当你希望控制消息的处理速度时,可能希望使用同步消费者。 Spring Cloud Stream 支持在给定应用程序的多个实例之间划分数据。在分区场景中,物理通信介质(如代理主题)被视为结构化为多个分区。一个或多个生产者应用程序实例将数据发送到多个消费者应用程序实例,并确保由公共特性标识的数据由同一个消费者实例处理。 Spring Cloud Stream 为以统一的方式实现分区处理用例提供了一个通用的抽象。因此,无论代理本身是自然分区(例如 Kafka)还是不分区(例如 RabbitMQ),都可以使用分区。 分区是状态处理中的一个关键概念,在这种情况下(出于性能或一致性原因),确保所有相关数据一起处理是至关重要的。例如,在时间窗口平均值计算示例中,任何给定传感器的所有测量都由同一应用程序实例处理是很重要的。
|
![[Note]](images/note.png)