|
要理解编程模型,你应该熟悉以下核心概念:
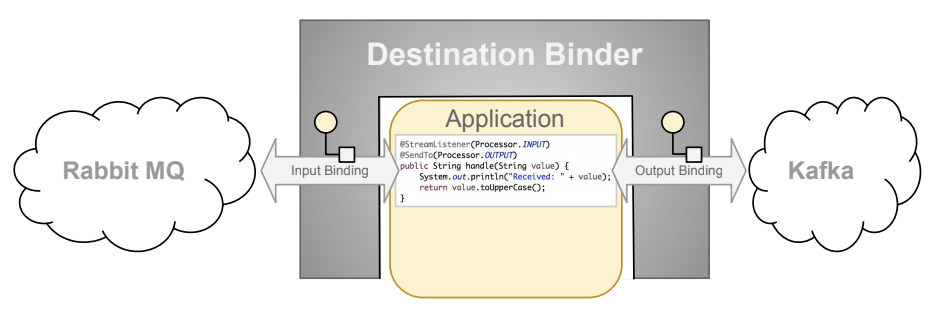 目的地绑定器是 Spring Cloud Stream 的扩展组件,负责提供必要的配置和实现,以促进与外部消息传递系统的集成。这种集成负责连接、委派和路由来自生产者和消费者的消息、数据类型转换、用户代码调用等。 绑定器处理很多样板文件的责任,否则将落在你的肩上。然而,要实现这一点,绑定器仍然需要一些以极简的形式提供的帮助,需要用户提供一组指令,这些指令通常以某种配置的形式提供。 虽然讨论所有可用的绑定器和绑定配置选项(手册的其余部分对它们进行了广泛的介绍)超出了本节的范围,但是 Destination Binding 确实需要特别注意。下一节将详细讨论它。 如前所述,Destination Bindings 在外部消息传递系统和应用程序提供的 Producers 和 Consumers 之间提供了一个桥梁。
将 @EnableBinding 注解应用到应用程序的一个配置类中,可以定义目标绑定。
下面的示例展示了一个完全配置且运行正常的 Spring Cloud Stream 应用程序,该应用程序以 @SpringBootApplication @EnableBinding(Processor.class) public class MyApplication { public static void main(String[] args) { SpringApplication.run(MyApplication.class, args); } @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public String handle(String value) { System.out.println("Received: " + value); return value.toUpperCase(); } }
如你所见, Spring Cloud Stream 已经为典型的消息交换契约提供了 binding 接口,其中包括:
public interface Sink { String INPUT = "input"; @Input(Sink.INPUT) SubscribableChannel input(); } public interface Source { String OUTPUT = "output"; @Output(Source.OUTPUT) MessageChannel output(); } public interface Processor extends Source, Sink {}
虽然前面的示例满足大多数情况,但是你也可以通过定义自己的绑定接口来定义自己的约定,并使用 例如: public interface Barista { @Input SubscribableChannel orders(); @Output MessageChannel hotDrinks(); @Output MessageChannel coldDrinks(); }
使用前面示例中所示的接口作为
你可以根据需要提供任意多的绑定接口,作为 @EnableBinding(value = { Orders.class, Payment.class })
在 Spring Cloud Stream 中,可绑定的 可轮询目标绑定 虽然前面描述的绑定支持基于事件的消息消耗,但有时你需要更多的控制,例如消耗率。 从 2.0 版开始,现在可以绑定可轮询的消费者: 下面的示例展示如何绑定可轮询的消费者: public interface PolledBarista { @Input PollableMessageSource orders(); . . . }
在这种情况下, 自定义通道名称
通过使用 public interface Barista { @Input("inboundOrders") SubscribableChannel orders(); }
在前面的示例中,创建的绑定通道命名为
通常,你不需要直接访问单个通道或绑定(然后通过 除了为每个绑定生成通道并将其注册为 Spring Bean 之外,对于每个绑定的接口,Spring Cloud Stream 还生成一个实现接口的 bean。这意味着你可以通过在应用程序中注入来访问表示绑定或单个通道的接口,如下两个示例所示: 注入绑定接口 @Autowire private Source source public void sayHello(String name) { source.output().send(MessageBuilder.withPayload(name).build()); } 注入单个通道 @Autowire private MessageChannel output; public void sayHello(String name) { output.send(MessageBuilder.withPayload(name).build()); }
您还可以使用标准 Spring 的 下面的示例展示如何以这种方式使用 @Qualifier 注解: @Autowire @Qualifier("myChannel") private MessageChannel output; 你可以使用 Spring 集成注解或 Spring Cloud Stream 本地注解来编写 Spring Cloud Stream 应用程序。 Spring Cloud Stream 建立在由企业集成模式定义的概念和模式的基础上,其内部实现依赖于 Spring 项目组合(Spring 集成框架)中已经建立并流行的企业集成模式的实现。 因此,支持 Spring 集成已经建立的基础、语义和配置选项是很自然的。
例如,可以将 @EnableBinding(Source.class) public class TimerSource { @Bean @InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "10", maxMessagesPerPoll = "1")) public MessageSource<String> timerMessageSource() { return () -> new GenericMessage<>("Hello Spring Cloud Stream"); } } 同样,在为 Processor 绑定约定提供消息处理程序方法的实现时,可以使用 @Transformer 或 @ServiceActivator,如下例所示: @EnableBinding(Processor.class) public class TransformProcessor { @Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT) public Object transform(String message) { return message.toUpperCase(); } }
作为对 Spring 集成支持的补充,Spring Cloud Stream 提供了自己的 @streamListener 注解,该注解是根据其他 Spring 消息注解( @EnableBinding(Sink.class) public class VoteHandler { @Autowired VotingService votingService; @StreamListener(Sink.INPUT) public void handle(Vote vote) { votingService.record(vote); } }
与其他 Spring 消息传递方法一样,方法参数可以用
对于返回数据的方法,必须使用 @EnableBinding(Processor.class) public class TransformProcessor { @Autowired VotingService votingService; @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public VoteResult handle(Vote vote) { return votingService.record(vote); } }
Spring Cloud Stream 支持将消息分派到多个处理程序方法,这些方法根据条件用 为了有资格支持条件分派,方法必须满足以下条件:
条件由注解的
在具有调度条件的 @EnableBinding(Sink.class) @EnableAutoConfiguration public static class TestPojoWithAnnotatedArguments { @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'") public void receiveBogey(@Payload BogeyPojo bogeyPojo) { // handle the message } @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bacall'") public void receiveBacall(@Payload BacallPojo bacallPojo) { // handle the message } }
使用 考虑以下情况: @EnableBinding(Sink.class) @EnableAutoConfiguration public static class CatsAndDogs { @StreamListener(target = Sink.INPUT, condition = "payload.class.simpleName=='Dog'") public void bark(Dog dog) { // handle the message } @StreamListener(target = Sink.INPUT, condition = "payload.class.simpleName=='Cat'") public void purr(Cat cat) { // handle the message } } 上述代码完全有效。它编译和部署没有任何问题,但是它从来不会产生你期望的结果。
那是因为你正在测试一些还没有在你期望的状态中存在的东西。这是因为消息的有效负载尚未从有线格式(
因此,除非使用计算原始数据的 SPeL 表达式(例如,字节数组中第一个字节的值),否则请使用基于消息头的表达式(例如,
从 Spring Cloud Stream V2.1 开始,定义 stream handlers 和 sources 的另一种选择是使用 Spring Cloud Function 的内置支持,它们可以被表示为
要指定要绑定到绑定公开的外部目标的功能 bean,必须提供
下面是将消息处理程序公开为 @SpringBootApplication @EnableBinding(Processor.class) public class MyFunctionBootApp { public static void main(String[] args) { SpringApplication.run(MyFunctionBootApp.class, "--spring.cloud.stream.function.definition=toUpperCase"); } @Bean public Function<String, String> toUpperCase() { return s -> s.toUpperCase(); } }
在上面的内容中,我们简单地定义了一个名为 toUpperCase 的 下面是支持源、处理器和接收器的简单功能应用程序的示例。
下面是定义为 @SpringBootApplication @EnableBinding(Source.class) public static class SourceFromSupplier { public static void main(String[] args) { SpringApplication.run(SourceFromSupplier.class, "--spring.cloud.stream.function.definition=date"); } @Bean public Supplier<Date> date() { return () -> new Date(12345L); } }
下面是定义为 @SpringBootApplication @EnableBinding(Processor.class) public static class ProcessorFromFunction { public static void main(String[] args) { SpringApplication.run(ProcessorFromFunction.class, "--spring.cloud.stream.function.definition=toUpperCase"); } @Bean public Function<String, String> toUpperCase() { return s -> s.toUpperCase(); } }
下面是定义为 @EnableAutoConfiguration @EnableBinding(Sink.class) public static class SinkFromConsumer { public static void main(String[] args) { SpringApplication.run(SinkFromConsumer.class, "--spring.cloud.stream.function.definition=sink"); } @Bean public Consumer<String> sink() { return System.out::println; } } 使用这个编程模型,你还可以从函数组合中获益,在函数组合中,你可以从一组简单函数中动态地组合复杂的处理程序。作为一个例子,我们将下面的函数 bean 添加到上面定义的应用程序中。 @Bean public Function<String, String> wrapInQuotes() { return s -> "\"" + s + "\""; }
并修改 —spring.cloud.stream.function.definition=toUpperCase|wrapInQuotes
使用轮询的消费者时,将按需轮询 public interface PolledConsumer { @Input PollableMessageSource destIn(); @Output MessageChannel destOut(); } 考虑到前面示例中的轮询的消费者,你可以按如下方式使用它: @Bean public ApplicationRunner poller(PollableMessageSource destIn, MessageChannel destOut) { return args -> { while (someCondition()) { try { if (!destIn.poll(m -> { String newPayload = ((String) m.getPayload()).toUpperCase(); destOut.send(new GenericMessage<>(newPayload)); })) { Thread.sleep(1000); } } catch (Exception e) { // handle failure } } }; }
与消息驱动的消费者一样,如果消息处理程序抛出异常,则消息将发布到错误通道,如 “???” 中所述。
通常, @Bean public ApplicationRunner poller(PollableMessageSource dest1In, MessageChannel dest2Out) { return args -> { while (someCondition()) { if (!dest1In.poll(m -> { StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).noAutoAck(); // e.g. hand off to another thread which can perform the ack // or acknowledge(Status.REQUEUE) })) { Thread.sleep(1000); } } }; }
还有一个重载的 poll(MessageHandler handler, ParameterizedTypeReference<?> type)
boolean result = pollableSource.poll(received -> { Map<String, Foo> payload = (Map<String, Foo>) received.getPayload(); ... }, new ParameterizedTypeReference<Map<String, Foo>>() {});
默认情况下,为可轮询源配置一个错误通道;如果回调引发异常,则会向错误通道发送一条
你可以使用
如果监听器直接抛出 错误会发生,Spring Cloud Stream 提供了几种灵活的机制来处理它们。错误处理有两种方式:
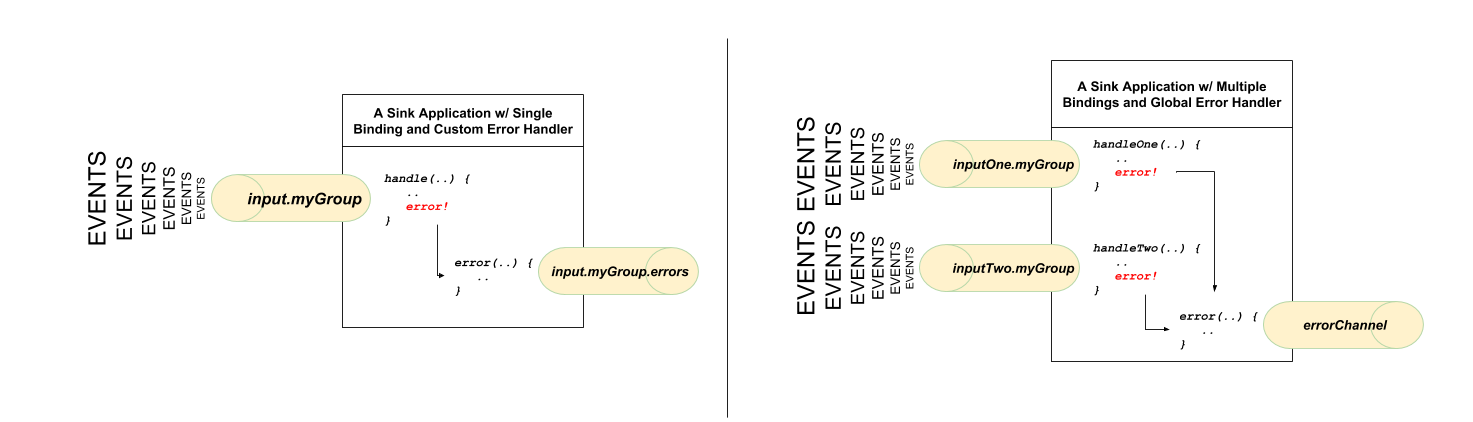
Spring Cloud Stream 使用 Spring Retry 库来促进成功的消息处理。有关详细信息,请参阅 小节 29.4.3, “重试模板”。但是,当所有操作都失败时,消息处理程序抛出的异常将传播回绑定器。此时,绑定器调用自定义错误处理程序或将错误传递回消息传递系统(重新排队、DLQ 和其他)。 有两种类型的应用程序级错误处理。可以在每个绑定订阅处处理错误,或者全局处理程序可以处理所有绑定订阅错误。让我们回顾一下细节。
对于每个输入绑定,Spring Cloud Stream 使用以下语义创建一个专用的错误通道
考虑以下事项: spring.cloud.stream.bindings.input.group=myGroup @StreamListener(Sink.INPUT) // destination name 'input.myGroup' public void handle(Person value) { throw new RuntimeException("BOOM!"); } @ServiceActivator(inputChannel = Processor.INPUT + ".myGroup.errors") //channel name 'input.myGroup.errors' public void error(Message<?> message) { System.out.println("Handling ERROR: " + message); }
在前面的示例中,目标名称是
此外,如果你绑定到现有目标,例如: spring.cloud.stream.bindings.input.destination=myFooDestination spring.cloud.stream.bindings.input.group=myGroup
完整的目标名称是 回到示例…
订阅名为
如果有多个绑定,则可能需要一个错误处理程序。Spring Cloud Stream 通过将每个错误通道桥接到名为 @StreamListener("errorChannel") public void error(Message<?> message) { System.out.println("Handling ERROR: " + message); } 如果错误处理逻辑相同,不管哪个处理程序产生了错误,这可能是一个方便的选项。 系统级的错误处理意味着错误被传回消息传递系统,并且,考虑到并非每个消息传递系统都是相同的,不同的绑定器之间的功能可能不同。 也就是说,在本节中,我们将解释系统级错误处理背后的一般思想,并以 Rabbit 绑定器为例。注意:Kafka 绑定器提供了类似的支持,尽管一些配置属性确实不同。此外,有关详细信息和配置选项,请参阅各个绑定器的文档。 如果没有配置内部错误处理程序,则错误将传播到绑定器,绑定器随后将这些错误传播回消息传递系统。根据消息传递系统的功能,此类系统可能会丢弃消息、重新排队以重新处理消息或将失败消息发送给 DLQ。Rabbit 和 Kafka 都支持这些概念。但是,其他绑定器可能不会,因此有关支持的系统级错误处理选项的详细信息,请参阅单个绑定器的文档。 DLQ 允许失败的消息被发送到一个特殊的目的地:死信队列。 配置后,失败的消息将发送到此目标,以进行后续的重新处理或审核和调节。 例如,继续上一个示例并使用 Rabbit 绑定器设置 DLQ,需要设置以下属性: spring.cloud.stream.rabbit.bindings.input.consumer.auto-bind-dlq=true
请记住,在上述属性中, 配置后,所有失败的消息都将路由到此队列,错误消息类似于: delivery_mode: 1
headers:
x-death:
count: 1
reason: rejected
queue: input.hello
time: 1522328151
exchange:
routing-keys: input.myGroup
Payload {"name”:"Bob"}
正如你从上面看到的,原始消息将被保留,以供进一步操作。 然而,你可能注意到的一件事是,对于消息处理的原始问题,信息是有限的。例如,看不到与原始错误对应的堆栈跟踪。要获取有关原始错误的更多相关信息,必须设置其他属性: spring.cloud.stream.rabbit.bindings.input.consumer.republish-to-dlq=true 这样做会强制内部错误处理程序截获错误消息,并在将其发布到 DLQ 之前向其添加其他信息。配置后,可以看到错误消息包含与原始错误相关的更多信息,如下所示: delivery_mode: 2
headers:
x-original-exchange:
x-exception-message: has an error
x-original-routingKey: input.myGroup
x-exception-stacktrace: org.springframework.messaging.MessageHandlingException: nested exception is
org.springframework.messaging.MessagingException: has an error, failedMessage=GenericMessage [payload=byte[15],
headers={amqp_receivedDeliveryMode=NON_PERSISTENT, amqp_receivedRoutingKey=input.hello, amqp_deliveryTag=1,
deliveryAttempt=3, amqp_consumerQueue=input.hello, amqp_redelivered=false, id=a15231e6-3f80-677b-5ad7-d4b1e61e486e,
amqp_consumerTag=amq.ctag-skBFapilvtZhDsn0k3ZmQg, contentType=application/json, timestamp=1522327846136}]
at org.spring...integ...han...MethodInvokingMessageProcessor.processMessage(MethodInvokingMessageProcessor.java:107)
at. . . . .
Payload {"name”:"Bob"}
这有效地结合了应用程序级和系统级的错误处理,以进一步帮助下游的故障排除机制。
如前所述,当前支持的绑定器(Rabbit 和 Kafka)依赖于 如果错误的性质与某些零星但短期的资源不可用有关,则此选项可能是可行的。 要完成此操作,必须设置以下属性: spring.cloud.stream.bindings.input.consumer.max-attempts=1 spring.cloud.stream.rabbit.bindings.input.consumer.requeue-rejected=true
在前面的示例中,
虽然前面的设置足以满足大多数自定义需求,但它们可能无法满足某些复杂的需求,此时你可能需要提供自己的 @StreamRetryTemplate public RetryTemplate myRetryTemplate() { return new RetryTemplate(); }
从上面的示例中可以看到,由于
Spring Cloud Stream 还支持使用响应式 API,其中传入和传出数据作为连续数据流处理。对响应式 API 的支持可以通过 带有响应式 API 的编程模型是声明性的。可以使用描述从入站到出站数据流的功能转换的运算符,而不是指定如何处理每个单独的消息。 目前,Spring Cloud Stream 只支持 Reactor API。在未来,我们打算支持一个更通用的基于响应流的模型。
响应式编程模型还使用
基于 Reactor 的处理程序可以具有以下参数类型:
基于 Reactor 的处理程序支持
以下示例显示了基于 Reactor 的 @EnableBinding(Processor.class) @EnableAutoConfiguration public static class UppercaseTransformer { @StreamListener @Output(Processor.OUTPUT) public Flux<String> receive(@Input(Processor.INPUT) Flux<String> input) { return input.map(s -> s.toUpperCase()); } } 使用输出参数的同一个处理程序如下所示: @EnableBinding(Processor.class) @EnableAutoConfiguration public static class UppercaseTransformer { @StreamListener public void receive(@Input(Processor.INPUT) Flux<String> input, @Output(Processor.OUTPUT) FluxSender output) { output.send(input.map(s -> s.toUpperCase())); } }
Spring Cloud Stream 响应式主持还提供了通过
本节中的剩余部分包括使用
以下示例每毫秒发出 @EnableBinding(Source.class) @EnableAutoConfiguration public static class HelloWorldEmitter { @StreamEmitter @Output(Source.OUTPUT) public Flux<String> emit() { return Flux.intervalMillis(1) .map(l -> "Hello World"); } }
在前面的例子中,
下一个例子是发送 Reactor @EnableBinding(Source.class) @EnableAutoConfiguration public static class HelloWorldEmitter { @StreamEmitter @Output(Source.OUTPUT) public void emit(FluxSender output) { output.send(Flux.intervalMillis(1) .map(l -> "Hello World")); } }
下一个例子在功能和风格上与上面的片段完全相同。但是,它不在方法上使用显式的 @EnableBinding(Source.class) @EnableAutoConfiguration public static class HelloWorldEmitter { @StreamEmitter public void emit(@Output(Source.OUTPUT) FluxSender output) { output.send(Flux.intervalMillis(1) .map(l -> "Hello World")); } }
本节中的最后一个示例是使用 Reactive Streams Publisher API 和利用 Spring Integration Java DSL 对它的支持的另一种编写响应式源的特色。下面的示例中的 @EnableBinding(Source.class) @EnableAutoConfiguration public static class HelloWorldEmitter { @StreamEmitter @Output(Source.OUTPUT) @Bean public Publisher<Message<String>> emit() { return IntegrationFlows.from(() -> new GenericMessage<>("Hello World"), e -> e.poller(p -> p.fixedDelay(1))) .toReactivePublisher(); } } |
![[Note]](images/note.png)
![[Important]](images/important.png)